
A RAID 5 uses block-level striping with parity data distributed across all member disks. RAID 5 has achieved popularity due to its low cost of redundancy. This can be seen by comparing the number of drives needed to achieve a given capacity. RAID 1 or RAID 0+1, which yield redundancy, give only s / 2 storage capacity, where s is the sum of the capacities of n drives used. In RAID 5, the yield is  . As an example, four 1TB drives can be made into a 2 TB redundant array under RAID 1 or RAID 1+0, but the same four drives can be used to build a 3 TB array under RAID 5. Although RAID 5 is commonly implemented in a disk controller, some with hardware support for parity calculations (hardware RAID cards) and some using the main system processor (motherboard based RAID controllers), it can also be done at the operating system level, e.g., using Windows Dynamic Disks or with mdadm in Linux. A minimum of three disks is required for a complete RAID 5 configuration. In some implementations a degraded RAID 5 disk set can be made (three disk set of which only two are online), while mdadm supports a fully-functional (non-degraded) RAID 5 setup with two disks - which function as a slow RAID-1, but can be expanded with further volumes.
. As an example, four 1TB drives can be made into a 2 TB redundant array under RAID 1 or RAID 1+0, but the same four drives can be used to build a 3 TB array under RAID 5. Although RAID 5 is commonly implemented in a disk controller, some with hardware support for parity calculations (hardware RAID cards) and some using the main system processor (motherboard based RAID controllers), it can also be done at the operating system level, e.g., using Windows Dynamic Disks or with mdadm in Linux. A minimum of three disks is required for a complete RAID 5 configuration. In some implementations a degraded RAID 5 disk set can be made (three disk set of which only two are online), while mdadm supports a fully-functional (non-degraded) RAID 5 setup with two disks - which function as a slow RAID-1, but can be expanded with further volumes.
In the example, a read request for block A1 would be serviced by disk 0. A simultaneous read request for block B1 would have to wait, but a read request for B2 could be serviced concurrently by disk 1.
RAID 5 parity handling
A concurrent series of blocks (one on each of the disks in an array) is collectively called a stripe. If another block, or some portion thereof, is written on that same stripe, the parity block, or some portion thereof, is recalculated and rewritten. For small writes, this requires...
- Read the old data block
- Read the old parity block
- Compare the old data block with the write request. For each bit that has flipped (changed from 0 to 1, or from 1 to 0) in the data block, flip the corresponding bit in the parity block
- Write the new data block
- Write the new parity block
The disk used for the parity block is staggered from one stripe to the next, hence the term distributed parity blocks. RAID 5 writes are expensive in terms of disk operations and traffic between the disks and the controller.
The parity blocks are not read on data reads, since this would be unnecessary overhead and would diminish performance. The parity blocks are read, however, when a read of blocks in the stripe and within the parity block in the stripe are used to reconstruct the errant sector. The CRC error is thus hidden from the main computer. Likewise, should a disk fail in the array, the parity blocks from the surviving disks are combined mathematically with the data blocks from the surviving disks to reconstruct the data on the failed drive on-the-fly.
This is sometimes called Interim Data Recovery Mode. The computer knows that a disk drive has failed, but this is only so that the operating system can notify the administrator that a drive needs replacement; applications running on the computer are unaware of the failure. Reading and writing to the drive array continues seamlessly, though with some performance degradation.
RAID 5 disk failure rate
The maximum number of drives in a RAID 5 redundancy group is theoretically unlimited, but it is common practice to limit the number of drives. The tradeoffs of larger redundancy groups are greater probability of a simultaneous double disk failure, the increased time to rebuild a redundancy group, and the greater probability of encountering an unrecoverable sector during RAID reconstruction.
As the number of disks in a RAID 5 group increases, the mean time between failures (MTBF, the reciprocal of the failure rate) can become lower than that of a single disk.
This happens when the likelihood of a second disk's failing out of N − 1 dependent disks, within the time it takes to detect, replace and recreate a first failed disk, becomes larger than the likelihood of a single disk's failing.
Worsening this issue has been a relatively stagnant unrecoverable read-error rate of disks for the last few years, which is typically on the order of one error in 1014 bits for SATA drives.[6] As disk densities have gone up drastically (> 1 TB) in recent years, it actually becomes probable with a ~10 TB array that an unrecoverable read error will occur during a RAID-5 rebuild.[6] Some of these potential errors can be avoided in RAID systems that automatically and periodically test their disks at times of low demand.[7] Expensive enterprise-class disks with lower densities and better error rates of about 1 in 1015 bits can improve the odds slightly as well. But the general problem remains that, for modern drives with moving parts that use most of their capacity regularly, the disk capacity is now in the same order of magnitude as the (inverted) failure rate, unlike decades earlier when they were a safer two or more magnitudes apart. Furthermore, RAID rebuilding pushes a disk system to its maximum throughput, virtually guaranteeing a failure in the short time it runs. Even enterprise-class RAID 5 setups will suffer unrecoverable errors in coming years, unless manufacturers are able to establish a new level of mass-storage reliability through lower failure rates or improved error recovery.
Nevertheless, there are some short-term strategies for reducing the possibility of failures during recovery.
RAID 6 provides dual-parity protection, allowing the RAID system to maintain single-failure tolerance until the failed disk has been replaced and the second parity stripe rebuilt. Some RAID implementations include a hot-spare disk to speed up replacement. Also, drive failures do not occur randomly, but follow the "bathtub curve". Most failures occur early and late in the life of the device, and are often connected to production in a way that skews the failures toward specific manufacturing lots. RAID vendors can try to avoid these lot-based problems by ensuring that all the disks in a redundancy group are from different lots.
Solid-state drives (SSDs) may present a revolutionary instead of evolutionary way of dealing with increasing RAID-5 rebuild limitations. With encouragement from many flash-SSD manufacturers, JEDEC is preparing to set standards in 2009 for measuring UBER (uncorrectable bit error rates) and "raw" bit error rates (error rates before ECC, error correction code).[8] But even the economy-class Intel X25-M SSD claims an unrecoverable error rate of 1 sector in 1015 bits and an MTBF of two million hours.[9] Ironically, the much-faster throughput of SSDs (STEC claims its enterprise-class Zeus SSDs exceed 200 times the transactional performance of today's 15k-RPM, enterprise-class HDDs)[10] suggests that a similar error rate (1 in 1015) will result a two-magnitude shortening of MTBF.
RAID 5 performance
RAID 5 implementations suffer from poor performance when faced with a workload which includes many writes which are smaller than the capacity of a single stripe.[citation needed] This is because parity must be updated on each write, requiring read-modify-write sequences for both the data block and the parity block. More complex implementations may include a non-volatile write back cache to reduce the performance impact of incremental parity updates.
Random write performance is poor, especially at high concurrency levels common in large multi-user databases. The read-modify-write cycle requirement of RAID 5's parity implementation penalizes random writes by as much as an order of magnitude compared to RAID 0.[11]
Performance problems can be so severe that some database experts have formed a group called BAARF — the Battle Against Any Raid Five.[12]
The read performance of RAID 5 is almost as good as RAID 0 for the same number of disks. Except for the parity blocks, the distribution of data over the drives follows the same pattern as RAID 0. The reason RAID 5 is slightly slower is that the disks must skip over the parity blocks.
In the event of a system failure while there are active writes, the parity of a stripe may become inconsistent with the data. If this is not detected and repaired before a disk or block fails, data loss may ensue as incorrect parity will be used to reconstruct the missing block in that stripe. This potential vulnerability is sometimes known as the write hole. Battery-backed cache and similar techniques are commonly used to reduce the window of opportunity for this to occur. The same issue occurs for RAID-6.
RAID 5 usable sizeParity data uses up the capacity of one drive in the array (this can be seen by comparing it with RAID 4: RAID 5 distributes the parity data across the disks, while RAID 4 centralizes it on one disk, but the amount of parity data is the same). If the drives vary in capacity, the smallest of them sets the limit. Therefore, the usable capacity of a RAID 5 array is 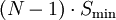 , where N is the total number of drives in the array and Smin is the capacity of the smallest drive in the array.
, where N is the total number of drives in the array and Smin is the capacity of the smallest drive in the array.
The number of hard disks that can belong to a single array is theoretically unlimited.
ZFS RAID 5
ZFS raid is based on the ideas behind RAID 5. It is similar to RAID-5 but uses variable stripe width to eliminate the RAID-5 write hole (stripe corruption due to loss of power between data and parity updates).[13]



 Firefox
Firefox
No comments:
Post a Comment