Der Begriff Serendipität (auch: Glücksfund, engl. Serendipity), gelegentlich auch Serendipity-Prinzip bzw. Serendipitätsprinzip,
bezeichnet eine zufällige Beobachtung von etwas ursprünglich nicht
Gesuchtem, das sich als neue und überraschende Entdeckung erweist.[1] Verwandt, aber nicht identisch, ist der weiter gefasste Begriff „glücklicher Zufall“. Serendipität betont zusätzlich „Untersuchung“; auch „intelligente Schlussfolgerung“ oder Findigkeit.
Auch im Bereich des Information Retrievals können Serendipitätseffekte eine Rolle spielen, wenn beispielsweise beim Surfen im Internet unbeabsichtigt nützliche Informationen entdeckt werden (dabei ist nicht der Zustand der Desorientierung in Hypertexten und virtuellen Informationsräumen gemeint, diesen bezeichnet man als Lost in Hyperspace).
Aber auch bei der Recherche in professionellen Datenbanken und
vergleichbaren Informationssystemen kann es zu Serendipity-Effekten
kommen. Hier wird die Serendipity zu einem Kennwert der Fähigkeit eines
Informationssystems, auch im eigentlichen Ballast nützliche
Informationen zu finden.
Der Wert der unten genannten Formel zeigt, wie weit ein
Informationssystem fähig ist, auch im Ballast einer Suche nützliche
Informationen zu finden.
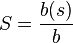
S: Serendipity
b(s): Anzahl der brauchbaren Dokumente im Ballast – wenn auch für ein anderes Suchargument!
b: Anzahl der für das Suchargument nicht relevanten Dokumente (siehe Recall und Precision)
Der Serendipity-Effekt ist nicht auf Hypertexte beschränkt, sondern tritt auch beim Stöbern in der Freihandaufstellung einer Bibliothek oder dem Angebot einer gut sortierten Buchhandlung auf.[2] Dafür wurde bereits lange vor dem Aufkommen des Internets der Begriff Browsing verwendet.



 Firefox
Firefox
No comments:
Post a Comment